
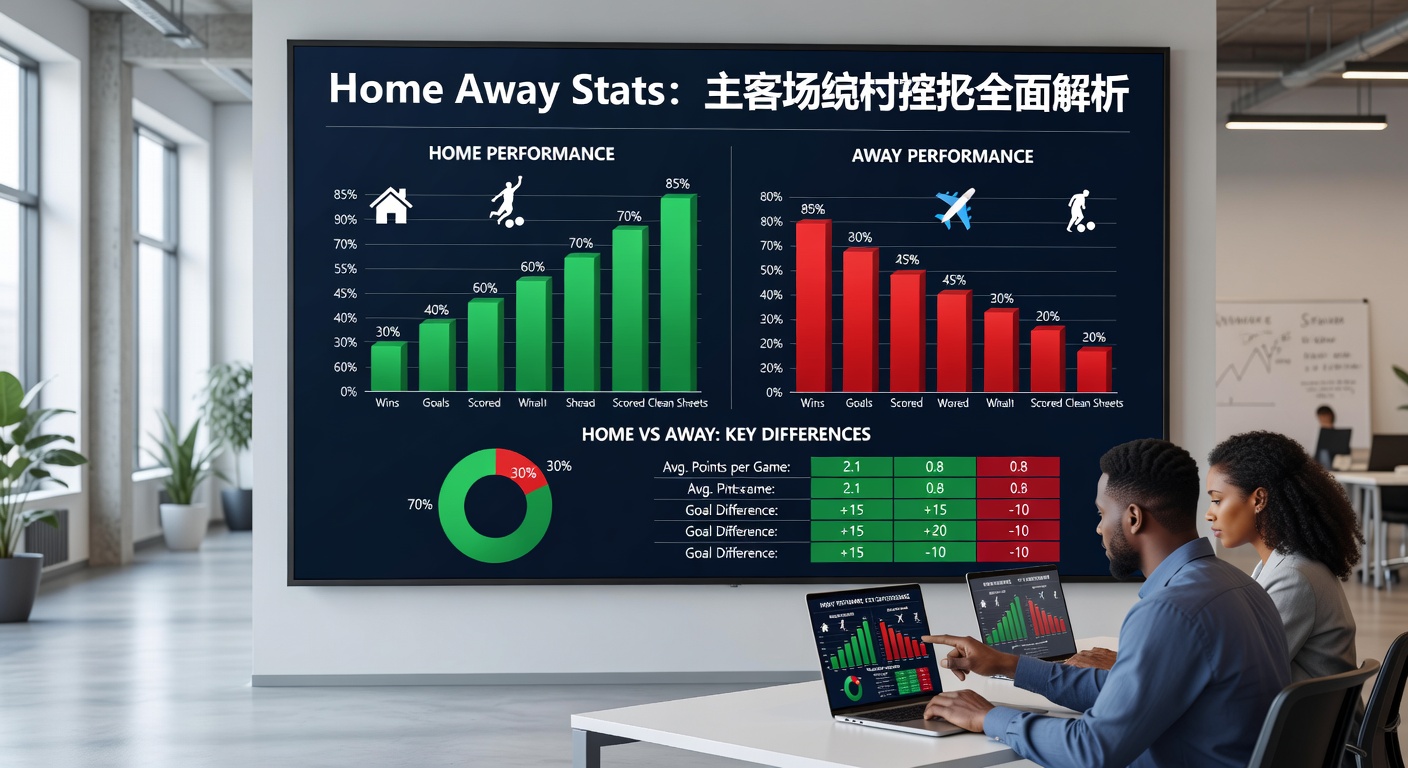
先看清楚搜索意图:为什么大家会查主客场数据
主客场数据 home away stats 这个词,我在做赛前观察时经常会碰到。站在资深分析师的角度看,用户搜它通常不是为了看一份孤立的统计表,而是想回答一个更实际的问题:这支球队在主场为什么更稳、客场为什么波动更大,以及这种差异是否会影响下一场比赛的判断。对于体育爱好者来说,它帮助理解球队真实强弱;对于更关注赛果的人来说,它则是筛选信息、减少误判的重要入口。
如果把搜索意图拆开看,通常会分成三层。第一层是基础认知,用户想知道主客场数据到底怎么看;第二层是实战比较,用户希望把主客场表现和近期状态、伤停、赛程强度一起放进判断框架里;第三层则更偏应用,尤其是对比赛走势、让球倾向、比分区间做预估时,主客场数据往往会成为一个高优先级变量。也正因为如此,这类关键词不是简单的“数据查询词”,而是典型的“分析决策词”。
从Google内容偏好来看,围绕这类词写作,最重要的不是把术语堆满,而是把信息组织成可理解、可比较、可复用的结构。也就是说,内容要回答“看什么”“怎么比”“何时参考”“何时不该过度依赖”。下面我会用更接近实战的方式,把主客场数据 home away stats 的核心逻辑拆开讲清楚,尽量让读者在看完后,能够直接把方法用到自己关心的比赛里。
主客场数据 home away stats 的核心:不是胜负表,而是环境差异表
很多人第一次接触主客场数据时,会把它简单理解成“主场赢了多少、客场输了多少”。这个理解只对了一半。更准确地说,主客场数据反映的是球队在不同比赛环境下的表现差异,而这种差异可能来自球迷氛围、旅行消耗、熟悉度、裁判尺度、战术部署甚至心理预期。换句话说,主客场数据不是单纯的结果统计,而是球队适应能力的外显。
在实际分析中,我通常会先把主客场数据拆成几个层次:结果层、过程层、节奏层和风险层。结果层看胜平负、进失球、净胜球;过程层看射门、控球、危险进攻、被压制时长;节奏层看比赛是更开放还是更保守;风险层则关注失误率、丢球集中时段、逆风局扳回能力。只有把这些层次叠起来,才不会被“主场强、客场弱”这种表面结论误导。
例如,有些球队主场看上去战绩出色,但过程数据并不稳定,往往是靠临门一脚效率或个别球员爆发撑起结果;还有些球队客场胜率一般,却在面对强队时反而能通过防守反击打出高质量表现。对这类队伍,如果只看胜率,就会把真实风格看偏。真正有用的主客场数据,应该能帮助你识别球队到底是“主场加成型”,还是“客场适应型”。
主场与客场的差别,常常体现在三个信号
第一是进攻节奏。主场球队往往更愿意提前压上,尤其在强势联赛或大球场氛围明显的环境里,开局前20分钟的逼抢强度通常会更高。第二是防守站位。客场作战时,很多球队会更重视阵型完整性和保护中路,避免因为压得太靠前而被对手打穿。第三是心理波动。主场球迷会放大领先优势,也会放大逆风时的焦躁,这种波动会直接体现在失误率和下半场表现上。
如果你做的是赛前判断,最值得注意的并不是“谁主谁客”本身,而是这种差异是否持续存在。短期的主客场波动可以被赛程、伤停、红黄牌、旅行时差放大;长期的主客场结构差异,则更能体现球队的真实底盘。因此,观察主客场数据时,至少应当拉开一个合理样本,不要只盯最近一两场的结果。
- 看样本时长:优先参考赛季累计数据,再结合最近5到10场走势。
- 看对手强度:主客场表现要分强弱对手分别统计,避免平均值失真。
- 看比赛状态:同样是客场,连续作战和充分休息的结果往往不同。
- 看战术稳定性:战术是否在主客场切换时发生明显变化。
怎么读主客场数据:从表面胜率走向实战判断
如果你想把主客场数据 home away stats 用在实战观察里,第一步不是看漂亮数字,而是问自己:这些数字是怎么来的。比如主场胜率高,究竟是因为对手整体偏弱,还是球队在主场确实能打出更高的压迫质量?客场失球多,是因为防线问题,还是因为球队在客场主动收缩后,反而把压力全部交给了门将?只有先找原因,数据才有意义。
一个实用的读数方法,是把主客场表现和比赛过程结合起来。比如,主场进球多但射门不算很多,可能意味着效率高;主场控球高但机会质量一般,可能意味着中场控制强但临门一脚不足;客场虽然丢球不少,但对强队的失球集中在最后阶段,可能说明体能和轮换是关键。也就是说,主客场数据并不是单点结论,而是线索集合。
对于更关注比赛走势的人来说,主客场数据还应该和盘口预期一起看,而不是孤立看。因为市场预期往往会把主场优势纳入基础判断,而真正的价值在于:球队的主场优势是否已经被过度定价,或者客场劣势是否被夸大。这个时候,主客场数据就不只是描述工具,而是校正认知的工具。
赛前最值得核对的四类主客场指标
下面这四类指标,通常比单纯的胜负更能帮助判断:
- 净胜球差:主客场的净胜球差能直接反映攻防平衡是否一致。
- 场均失球:客场失球升高,往往提示防线保护或对抗强度不足。
- 先丢球后的反应:落后时能否快速扳回,是衡量心理韧性的关键。
- 强队对抗表现:面对排名靠前球队时,主客场数据是否明显分化。
这四项并不复杂,但它们往往比“赢了几场”更能解释问题。尤其是在密集赛程下,球队容易出现主场表现好、客场不稳定的阶段性结构,这时候如果只看结果,就可能错过真正的变化。对搜索主客场数据的人来说,最需要的其实就是这种“能直接转化成判断”的信息。
“主客场数据的价值,不在于证明一支球队有多强,而在于揭示它在不同环境下的稳定性边界。”
行业报告
这句话放到实战里非常贴切。因为一支球队即使总排名不错,也可能存在明显的客场短板;反过来,一支排名中游的球队也可能拥有相当稳定的客场抗压能力。真正影响后续判断的,不是绝对名次,而是这种边界是否清晰、是否可重复。
结合赛事节奏与赛程强度,主客场数据才更接近真实
很多文章讲主客场数据时,会把它写成静态表格,但真实比赛从来不是静态的。赛程密度、旅行距离、休息天数、杯赛分心、伤停变化,都会让主客场差异发生偏移。尤其在2026年赛季节奏更快、轮换更频繁的背景下,主客场数据的解释方法也需要更灵活。只看赛季平均数已经不够了,还要看趋势和情境。
举个简单的例子。某支球队在主场的强势可能建立在连续两周休整的基础上,而到了客场,由于中间夹着长途飞行或双赛任务,攻防衔接就明显下降。此时,你如果只看“主场强、客场弱”的标签,得到的结论并不完整。正确做法是把主客场数据和赛程节奏叠加,判断球队到底是整体实力不足,还是只是在高负荷环境下表现下滑。
另外,赛事类型也会改变主客场数据的含义。联赛、杯赛、淘汰赛、两回合对抗,对主客场的重视程度都不同。联赛里,样本足够大,主客场数据更能体现整体稳定性;杯赛里,单场偶然性更强,主客场优势可能被阵容轮换和战意因素稀释;两回合比赛里,首回合和次回合的主客场角色还会直接影响策略选择。
不同赛事下,主客场数据的观察重点会变
- 联赛:看长期稳定性,关注主客场得失球和连续性。
- 杯赛:看轮换幅度,关注主力出场率和战术保守程度。
- 淘汰赛:看首回合策略,主客场通常和风险控制强相关。
- 友谊赛:主客场参考价值下降,更应看阵容与试验目的。
这也是为什么我建议读者在查主客场数据时,先明确自己要用于什么场景。如果是纯粹了解球队结构,那么赛季累计数据足够;如果是赛前判断,就要更强调最新5到8场的状态变化;如果是关注走势,那么还应结合阵容、打法、强度和预期节奏一起看。主客场数据本身并不难,难的是把它放回正确的比赛语境里。
在内容表达上,这类图示最重要的作用不是“美观”,而是帮助读者快速建立层级感:先看结果,再看过程,最后回到比赛背景。对移动端用户尤其如此,因为他们通常希望用更少的时间获得更高密度的信息。
实战里最常见的误区:为什么主客场数据会被读偏
主客场数据之所以常常被误读,核心原因是很多人习惯把它当成结论,而不是过程证据。最常见的误区之一,是用少量样本下结论。比如一支球队刚在主场连赢两场,就被认为“主场无敌”;刚在客场连续输球,就被判断为“客场崩盘”。这种判断方式太快,也太容易被短期波动带偏。
第二个误区,是忽略对手质量。主场数据好,不代表球队在任何主场对任何对手都好。若主场胜利主要来自对阵下游球队,那么面对高压逼抢、强转换效率的对手时,主场优势未必还能延续。客场数据同理,若球队客场失利集中在强强对话,那么它也许并不是“不会打客场”,而是“面对高质量对手时缺乏控制力”。
第三个误区,是过分相信平均值。平均值能给你一个轮廓,但很难告诉你波动结构。比如某队主客场进球均值相近,但主场比赛更容易早早领先,客场则常常后程失守。平均值会把这些差异抹平,而实战判断恰恰需要识别这些被抹平的部分。
避免误读的三条实用原则
- 原则一:先看样本大小,再看结论是否稳定。
- 原则二:先分对手层级,再比较主客场差异。
- 原则三:先看比赛过程,再看结果是否可复制。
如果把这三条原则长期坚持下来,你会发现主客场数据的价值会明显提升。它不再只是一个“好像有点用”的表格,而会变成一个很稳的筛选器:帮助你识别哪些球队值得继续关注,哪些球队的主客场表现其实只是短期噪音。
“主客场差异最大的风险,不是数据不好看,而是把短期波动误当成长期规律。”
权威分析
这类提醒看似简单,但在实战里非常关键。很多判断失误,并不是因为没有数据,而是因为没有分清短期异常和长期结构。真正成熟的观察方式,应该允许数据波动存在,同时也尊重长期趋势的力量。
把主客场数据转成可执行判断:适合体育爱好者与观察型玩家的思路
如果你是体育爱好者,主客场数据最有价值的地方,在于它能帮助你更快理解球队风格:谁更依赖主场气势,谁更擅长客场控节奏,谁在强压之下容易失真,谁在逆境里反而更稳。如果你更关注赛前判断,那么主客场数据就要和状态曲线、伤停名单、战术变化一起使用,单独看任何一个维度都容易偏。
我自己的习惯是,把主客场数据分成“基础层”和“决策层”。基础层是:主客场胜负、进失球、场均表现、连续性;决策层是:对不同强度对手的表现、领先和落后时的变化、是否存在明显节奏倾向、是否受赛程影响明显。基础层帮助你认识球队,决策层帮助你判断比赛。
如果要进一步细化,还可以把主客场数据与比赛节奏对应起来。比如:
- 主场高压型:更容易在开局阶段拿到优势,但后段体能要重点观察。
- 客场保守型:往往失球不算多,但进攻端稳定性较弱。
- 主客场双向稳定型:这类球队通常更有持续参考价值。
- 主客场分裂型:主强客弱或主弱客强,最值得结合对手风格深挖。
对于这四种类型,读法并不相同。高压型球队主场看起来很强,但如果近期伤停影响前场逼抢,那么它的主场优势可能会快速缩水;保守型球队客场可能不容易输大,但如果落后能力不足,比赛走势就会越来越被动;双向稳定型球队通常是分析时的“低噪音样本”;分裂型球队则最需要找出差异来源,因为它们往往既能制造机会,也可能在某些环境里迅速失控。
站在内容收录与排名的角度,写主客场数据 home away stats 时,文章最好覆盖这几类典型疑问:什么是主客场差异、为什么主客场数据重要、怎么读、怎么避免误判、如何应用到具体比赛。这些都是用户真实会追问的问题,也更容易形成稳定的搜索匹配。
最后要强调一点:主客场数据不是孤立的决定性指标,但它通常是最先该被检查的指标之一。原因很简单,它直接对应了比赛环境,而比赛环境本身就是影响结果的重要变量。你可以把它当成判断的起点,而不是终点。
从长期观察来看,真正有参考价值的主客场数据,往往具备三个特征:样本足、差异稳定、能够解释比赛过程。如果三者都成立,那么它对赛前观察的帮助就会非常明显;如果三者只成立一部分,那就要降低权重,避免过度解读。理解这一点之后,你看主客场数据 home away stats 的方式会更接近专业分析,而不是停留在表面胜负。